 玩币族移动版
玩币族移动版




碾压H100!英伟达GH200超级芯片首秀MLPerf v3.1,性能跃升17%
时间:2023-09-12 来源:区块链网络 作者:AI梦工厂
来源:新智元 继4月份加入LLM训练测试后,MLPerf再次迎来重磅更新! 刚刚,MLCommons发布了MLPerf v3.1版本更新,并加入了两个全新基准:LLM推理测试MLPerf Inference v3.1,以及存储性能测试MLPerf Storage v0.5。 而这,这也是英伟达GH200测试成绩的首次亮相! 相比于单张H100配合英特尔CPU,GH200的Grace CPU+H100 GPU的组合,在各个项目上都有15%左右的提升。   英伟达GH200超级芯片首秀 英伟达GH200超级芯片首秀毫无疑问,英伟达的GPU在MLPerf Inference 3.1基准测试中表现是最亮眼的。  其中,最新发布的GH200 Grace Hopper超级芯片,也是首次在MLPerf Inference 3.1上亮相。 Grace Hopper超级芯片将英伟达的Grace CPU与H100 GPU集成在一起,通过超高的带宽连接,从而比单个H100配合其他的CPU能提供更强的性能表现。 「Grace Hopper首次展示了非常强劲的性能,与我们的H100 GPU提交相比,性能提高了17%,我们已经全面领先,」英伟达人工智能总监Dave Salvator在新闻发布会上表示。 性能大幅增长具体来说,它将一个H100 GPU和Grace CPU集成在一起,通过900GB/s的NVLink-C2C连接。 而CPU和GPU分别配备了480GB的LPDDR5X内存和96GB的HBM3或者144GB的HBM3e的内存,集成了高达576GB以上的高速访问内存。  英伟达GH200 Grace Hopper超级芯片专为计算密集型工作负载而设计,能够满足各种严苛的要求和各项功能。 比如训练和运行数万亿参数的大型Transformer模型,或者是运行具有数TB大小的嵌入表的推荐系统和向量数据库。 GH200 Grace Hopper超级芯片还在MLPerf Inference测试中有着非常优异的表现,刷新了英伟达单个H100 SXM在每个项目中创下的最佳成绩。 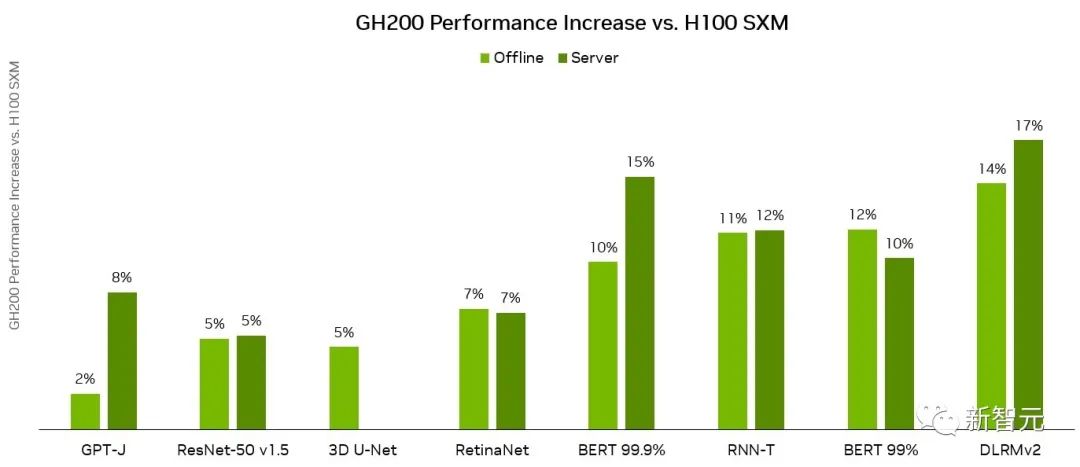 NVIDIA Grace Hopper MLPerf Inference数据中心性能与DGX H100 SXM的对比结果,每个数值都是GH200的性能领先幅度 GH200 Grace Hopper超级芯片集成了96 GB的HBM3,并提供高达4 TB/s的HBM3内存带宽,而H100 SXM分别为80 GB和3.35 TB/s。 与H100 SXM相比,更大的内存容量和更大的内存带宽使得在NVIDIA GH200 Grace Hopper超级芯片上使用更大的批处理大小来处理工作负载。 例如,在服务器场景中,RetinaNet和DLRMv2的批处理大小都增加了一倍,在离线场景中,批处理大小增加了50%。 GH200 Grace Hopper超级芯片在Hopper GPU和Grace CPU之间的高带宽NVLink-C2C连接可以实现CPU和GPU之间的快速通信,从而有助于提高性能。 例如,在MLPerf DLRMv2中,在H100 SXM上通过PCIe传输一批张量(Tensor)大约需要22%的批处理推理时间。 使用了NVLink-C2C的GH200 Grace Hopper超级芯片仅使用3%的推理时间就完成了相同的传输。 由于具有更高的内存带宽和更大的内存容量,与MLPerf Inference v3.1的H100 GPU相比,Grace Hopper超级芯片的单芯片性能优势高达17%。 推理和训练全面领先在MLPerf的首秀中,GH200 Grace Hopper Superchip在封闭类别(Closed Division)的所有工作负载和场景上都表现出卓越的性能。 而在主流的服务器应用中,L4 GPU能够提供一个低功耗,紧凑型的算力解决方案,与CPU解决方案相比的性能也有了大幅的提升。 Salvator表示,「与测试中最好的x86 CPU相比,L4的性能也非常强劲,提高了6倍」。  对于其他的AI应用和机器人应用,Jetson AGX Orin和Jetson Orin NX模块实现了出色的性能。 未来的软件优化有助于进一步释放强大的英伟达Orin SoC在这些模块中的潜力。 在目前非常流行的目标检测AI网络——RetinaNet上,英伟达的产品的性能提高了高达84%。 英伟达开放部分(Open Division)的结果,展示了通过模型优化可以在保持极高精度的同时大幅提高推理性能的潜力。 全新MLPerf 3.1基准测试当然,这并不是MLCommons第一次尝试对大语言模型的性能进行基准测试。 早在今年6月,MLPerf v3.0就首次加入了LLM训练的基准测试。不过,LLM的训练和推理任务,区别很大。 推理工作负载对计算要求高,而且种类繁多,这就要求平台能够快速处理各种类型的数据预测,并能在各种AI模型上进行推理。 对于希望部署AI系统的企业来说,需要一种方法来客观评估基础设施在各种工作负载、环境和部署场景中的性能。 所以对于训练和推理的基准测试都是很重要的。 MLPerf Inference v3.1包括了两项重要更新,来更好地反映现在AI实际的使用情况: 首先,增加了基于GPT-J的大型语言模型 (LLM)推理的测试。GPT-J是一个开源的6B参数LLM,对CNN/每日邮报数据集进行文本总结。  除了GPT-J之外,这次还更新了DLRM测试。 针对MLPerf Training v3.0中引入的DLRM,采用了新的模型架构和更大的数据集,更好地反映了推荐系统的规模和复杂性。 MLCommons创始人兼执行董事David Kanter表示,训练基准侧重于更大规模的基础模型,而推理基准执行的实际任务,则代表了更广泛的用例,大部分组织都可以进行部署。 在这方面,为了能够对各种推理平台和用例进行有代表性的测试,MLPerf定义了四种不同的场景。  每个基准都由数据集和质量目标定义。 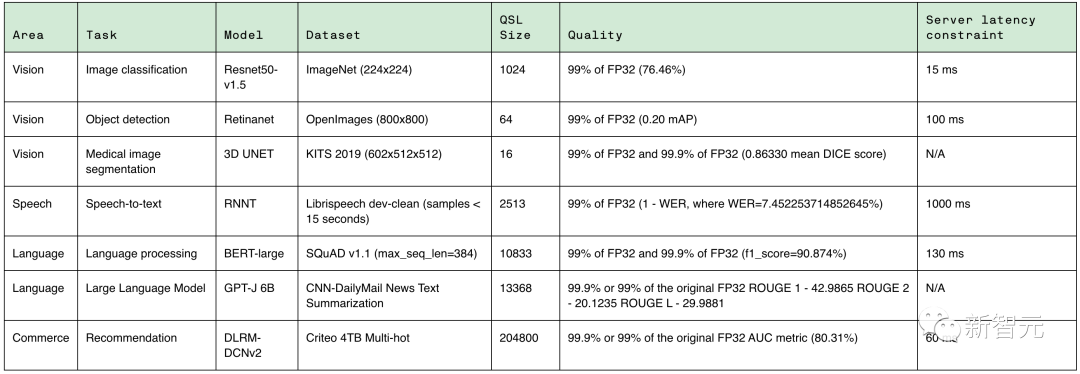 每个基准都需要以下场景: 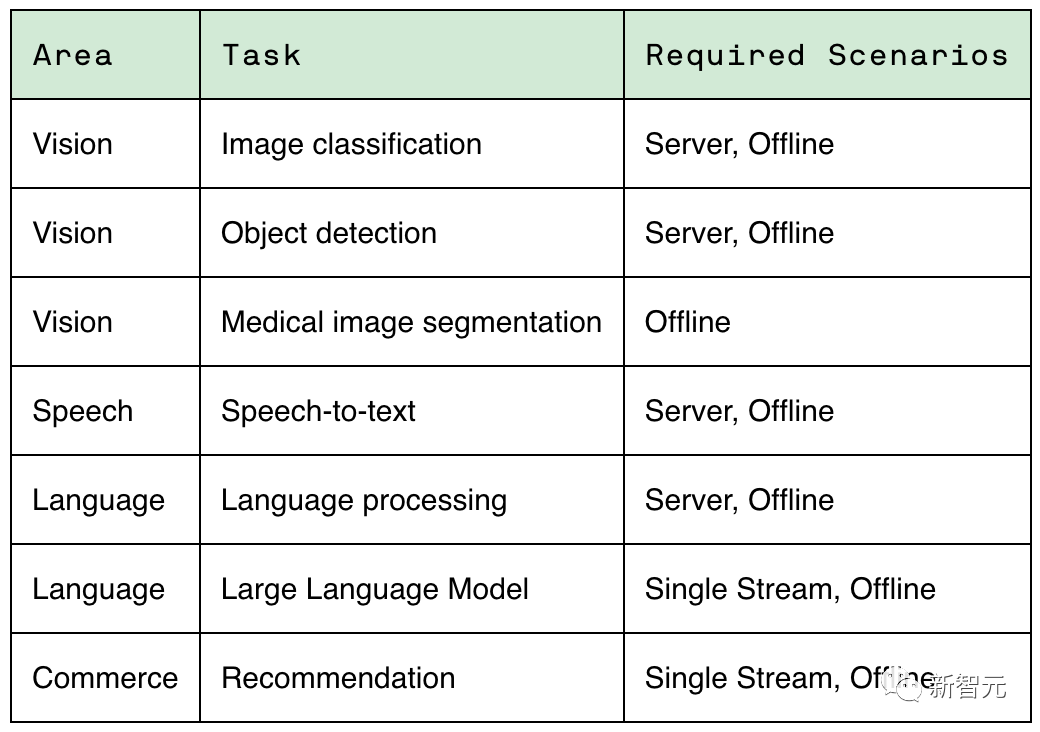 在MLPerf v3.1基准测试中,有超过13,500个结果,其中不少提交者的性能比3.0基准提高了20%,甚至更多。 其他提交者包括华硕,Azure,cTuning,Connect Tech,戴尔,富士通,Giga Computing,谷歌,H3C,HPE,IEI,英特尔,Intel Habana Labs,Krai,联想,墨芯,Neural Magic,Nutanix,甲骨文,高通,Quanta Cloud Technology,SiMA,Supermicro,TTA和xFusion等。 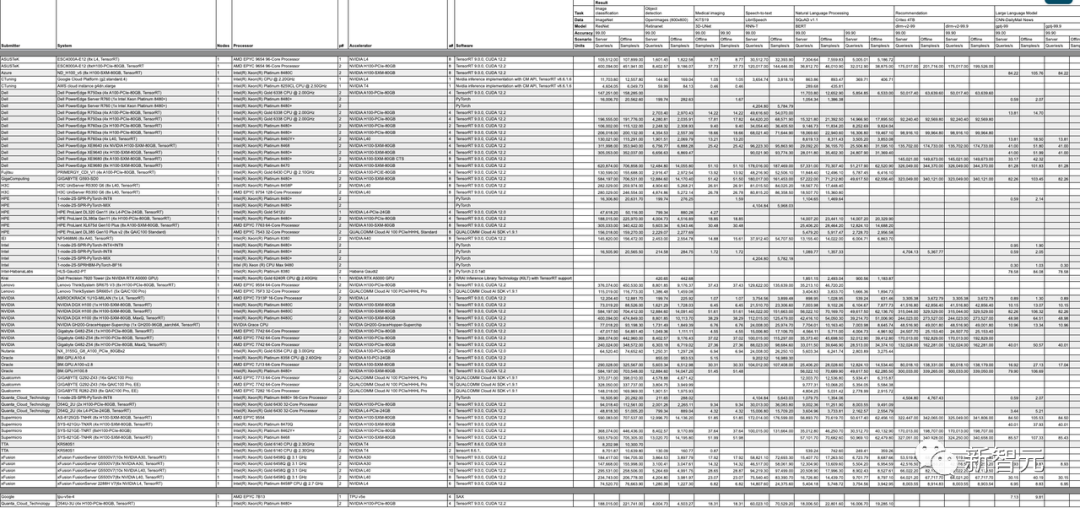 详细数据:https://mlcommons.org/en/inference-datacenter-31/ 参考资料: https://developer.nvidia.com/blog/leading-mlperf-inference-v3-1-results-gh200-grace-hopper-superchip-debut/?ncid=so-twit-408646&=&linkId=100000217826658 https://mlcommons.org/en/inference-datacenter-31/ https://venturebeat.com/ai/mlperf-3-1-adds-large-language-model-benchmarks-for-inference/ |