 玩币族移动版
玩币族移动版




训练成本降低16倍,极限压缩42倍!开源文本生成图片模型
时间:2023-09-18 来源:区块链网络 作者:AIcore
原文来源:AIGC开放社区  图片来源:由无界 AI? 生成 Stable Diffusion是目前最强开源文本生成图片的扩散模型之一,但对于那些没有A100、H100的中小企业、个人开发者来说有一个很大缺点,需要花费高昂的训练成本。 为了解决这一痛点,Wuerstchen开源模型采用了一种全新的技术架构,在保证图片质量的情况下实现了42倍极限压缩。以512x512尺寸的训练图片为例,Stable Diffusion1.4需要150,000小时的GPU训练时间,而Wuerstchen仅需要 9,000小时,训练成本降低了16倍。 即便是图片分辨率高达1536,Wuerstchen也只需要24,602小时,训练成本仍然比Stable Diffusion便宜6倍。 所以,该开源产品有利于那些没有庞大算力的开发者去尝试扩散模型,同时可以在此基础之上探索更好的训练方法。 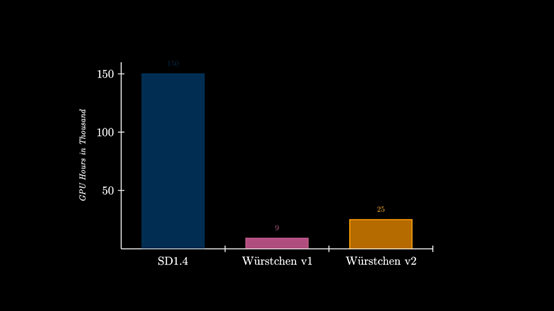 开源地址:https://huggingface.co/warp-ai/wuerstchen? Github:https://github.com/dome272/Wuerstchen? 论文:https://arxiv.org/abs/2306.00637<br/>? Wuerstchen简单介绍Wuerstchen扩散模型采用了一种,在图像的高度压缩的潜在空间中的工作方法。这也是其训练成本比Stable Diffusion低的原因之一。 压缩数据可以将训练和推理的成本减少几个数量级。例如,在1024×1024的图像上训练肯定要比32×32上训练贵得多。通常业内采用的压缩范围在4—8倍左右。 而Wuerstchen通过全新的技术架构将压缩发挥到极限,实现了42倍空间压缩,这是史无前例的技术突破!因为一旦超过16倍压缩,普通方法根本无法实现图片的重建。 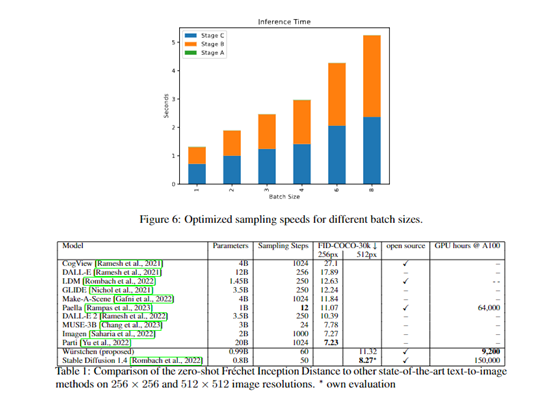 Wuerstchen极限压缩原理 Wuerstchen极限压缩原理Wuerstchen的极限压缩方法分为A、B、C三个阶段:A阶段)进行初始训练,并采用向量量化生成对抗网络 (VQGAN) 来创建离散化潜在空间,将数据映射到一个预定义的、较小的集合中的点,这种紧凑的表示形式有助于模型学习和推理速度; B阶段)进一步压缩,使用一个编码器将图像投影到一个更加紧凑的空间,和一个解码器试图从编码的图像中重建VQGAN的潜在表达。 并使用了基于Paella模型的标记预测器来完成这个任务。该模型是在编码图像的表示的条件下进行的,可以使用更少的采样步骤数量进行训练,这对于提升算力效率帮助巨大。 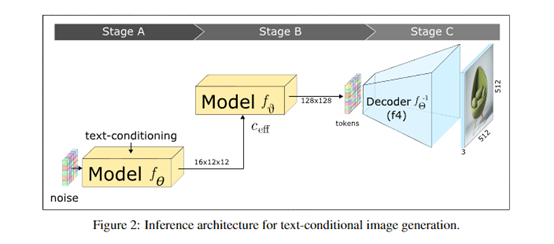 C阶段)使用A、B的图像编码器将图像投射到紧凑的潜在空间,训练一个文本条件的潜在扩散模型,并显著减少空间维度。这个离散的潜在空间允许模型生成,更具有多样性和创新性的图像,同时还保留了图片的高质量特征。  Wuerstchen可以生成的图片尺寸 Wuerstchen接受了 1024x1024 和1536x1536分辨率之间的图像训练数据,输出的图片质量非常稳定。即便是1024x2048这样的非对等图片,同样可以得到很好的效果。  开发者还发现,Wuerstchen对新分辨率图片的训练适应能力非常强,在2048x2048分辨率图片下进行数据微调,同样能极大降低成本。 Wuerstchen生成图片展示根据Wuerstchen展示的案例,该模型对文本的理解能力非常好,生成的质量效果也能媲美Stable Diffusion等目前最强开源扩散模型。 一只穿着白大褂的鹰的真实照片  两名星球大战里的冲锋队员,坐在酒吧里喝啤酒  蜜蜂打扮成宇航员的高度真实照片  一只戴着黑色礼貌的老鼠  |